Session 4 Prior Distributions
- Learn different ways of selecting and constructing priors
- Prior distributions used in clinical studies
- Introduction to hierarchical priors for random effects
- Introduction to sparsity promoting prior for Bayesian regression variable selection
4.1 Choosing priors
Types of prior
Generally speaking, there are two types of priors: informative and noninformative.
Priors with information on values of parameters, informative priors
- Priors that charaterize personal/expert opinion
- Prior elicitation
- Historical data or past evidence
- Default priors in clincial studies
- Informative priors used for computational efficiency and variable selection
“objective” and non-informative priors
- Flat prior, vague prior, and weakly-informative priors
Important consideration before choosing a prior
- Choice of prior does affect the posterior, however, prior is only one part of Bayesian modelling.
- Prior is not unique and there is no one “correct” prior distribution!
- In many situations with large sample sizes, the posterior distribution is not too sensitive to reasonable changes in prior.
- When working with rare outcomes (e.g., small disease cohort), changes in prior distribution can influence posterior distribution
- One criticism of Bayesian inference is in its incorporation of priors, which is considered as a subjective modelling choice.
- However, any statistical analysis is inherently subjective, frequentist or Bayesian.
- “Subjective” choice of prior can often be beneficial
- Sensitivity analysis is crucial in assessing the impact of particular distributions on the conclusions.
- when we are working with small samples, informative prior allows us to explicitly incorporate past evidence and expert knowledge
- we can also use sparsity promoting prior (i.e., shrinkage prior) to reduce the number of parameters to be estimated to improve estimation efficiency and avoid over-fitting
4.1.1 Eliciting priors from experts
Elicitation is the process of
- representing the knowledge of one or more experts - expert knowledge is useful!
- concerning an uncertain quantity as a probability distribution for that quantity (i.e. as a random variable with some distribution)
Good elicitation methods are formal, statistically rigorous, and use carefully considered probabilistic judgement techniques
in practice, elicitation follows pre-developed elicitation protocol
elicitation process often involve training and discussion between experts and statisticians to eliminate bias, mis-interpretation, over-optimistic thinking …
Aggregating expert judgement
There are two general approaches to summarizing the estimates from the experts.
- Aggregate the distributions
- Elicit a distribution from each expert separately
- Combine these multiple distribution using mathematical aggregation, also called “pooling”
- Aggregate the experts
- gather expert belief and elicit a single distribution, also called behavioural aggregation.
Three protocols
- Most popular. Sheffield Elicitation Framework (SHELF). The SHELF protocol is a behavioral aggregation method that uses two rounds of judgments. (O’Hagan et al. 2006)
- In the first round, individuals make private judgements
- In the second round, those judgments are reviewed before the group agrees on consensus judgement.
- Cooke protocol. A mathematical aggregation approach weights expert responses by their likely accuracy. (Cooke et al. 1991)
- The likely accuracy is calculated using a “seed” value.
- Expert who more accurately predict the seed value are weighted more.
- Delphi Method The Delphi is similar to SHELF as it is a behavioral aggregation method with two or more rounds except that anonymity is maintained in terms of who gave which answers.
- unlike SHELF, experts provide their judgments individually with no interaction and a pooling rule is required across expert final distributions.
Reference reading on expert elicitation:
- Methods to elicit beliefs for Bayesian priors: a systematic review (2010), by johnson et al. (S. R. Johnson, Tomlinson, Hawker, Granton, and Feldman 2010)
- Reviewed on measurement properties including validity, reliability, responsiveness, and feasibility (lacking in exisiting work).
- A valid and reliable method (S. R. Johnson, Tomlinson, Hawker, Granton, Grosbein, et al. 2010)
- Uncertain judgements: eliciting experts’ probabilities (2006) by O’Hagan et al. (O’Hagan et al. 2006)
- SHELF documentation and software: http://www.jeremy-oakley.staff.shef.ac.uk/shelf/software/
- Dr. Anthony O’Hagan’s talk on elicitation and SHELF: https://www.youtube.com/embed/cU4Cd8CGiaM
Tutorial example on SHELF framework - Elicitation workshop for Bronchiolitis in Infants Placebo Versus Epinephrine and Dexamethasone (BIPED) study (project manuscript under review)
Principal Investigator for the Elicitation Study: Dr. Anna Heath, PhD, MMath, The Hospital for Sick Children, Toronto
Research Assistant and ShinyApp Developer: Jingxian (Phebe) Lan, M.Sc
4.2 Default clincial priors
Section 5.5 Default Priors of (David J. Spiegelhalter, Abrams, and Myles 2003)
4.2.1 “Non-informative” or “reference” priors
- (Pros) It is attractive to seek a “noninformative”
prior to use as a baseline analysis
- “such analyses have been suggested as a way of making probability statements about parameters without being explicitly Bayesian” (David J. Spiegelhalter 2004)
- (Cons) However, nonninformative priors are nonsensical and can lead to inference problems, especially in smaller samples
- can have a strong impact particularly when events are rare.
- Prior Choice Recommendations and Wiki developed by the stan team, https://github.com/stan-dev/stan/wiki/Prior-Choice-Recommendations
- this guide is written by statisticians, thus, recommendations are primary for non-informative, vague, and weakly informative priors
- General principle on this guide provides a start
1. Noninformative Prior on Proportion
Suppose you are estimating the 30-day mortality after elective non-cardiac surgery, what is an uninformative prior for the proportion dying?
- An “off the shelf” uninformative priors for binomial model are
- \(\theta \sim U(0,1) \equiv Beta(1,1)\)
- Jeffreys prior, \(\theta \sim Beta(0.5,0.5)\)
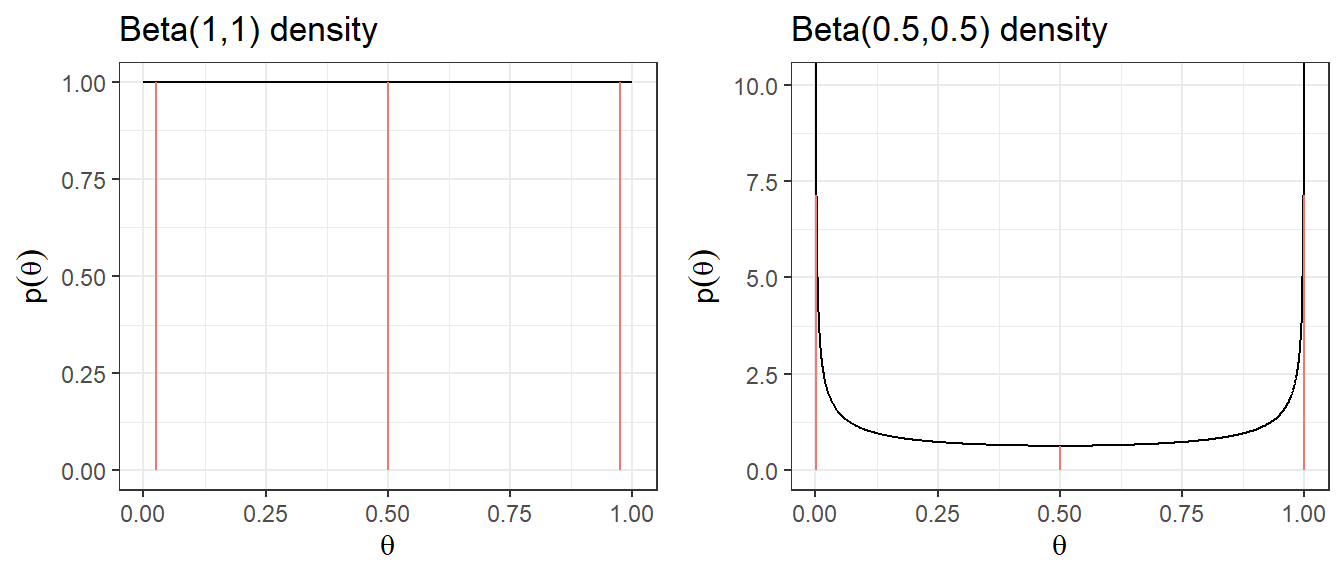
| Prior | median | q2.5 | q97.5 | Pr(\(\theta\)< 0.25) | Pr(\(\theta\)< 0.5) | Pr(\(\theta\)< 0.75) |
|---|---|---|---|---|---|---|
| Beta(1,1) | 0.5 | 0.025 | 0.975 | 0.25 | 0.5 | 0.75 |
| Beta(0.5,0.5) | 0.5 | 0.002 | 0.998 | 0.333 | 0.5 | 0.667 |
2. Noninformative Prior on log-relative risk
Suppose you want to estimate the relative risk for death in a clinical trial
Relative risk modelling works with the log-relative risk (as it has an approximately normal likelihood)
An “off the shelf” uninformative prior with a large variance might be \[\log(RR) = \theta \sim N(0, \sigma^2 = 10^2)\]
Prior 95% Credible Interval for log(RR) is -19.6 to 19.6
Prior 95% Credible Interval for RR is \(3 \times 10^{-9}\) to \(3 \times 10^{9}\)
A more sensible choice, \(N(0,5^2)\), for log scale OR, RR, and HR.
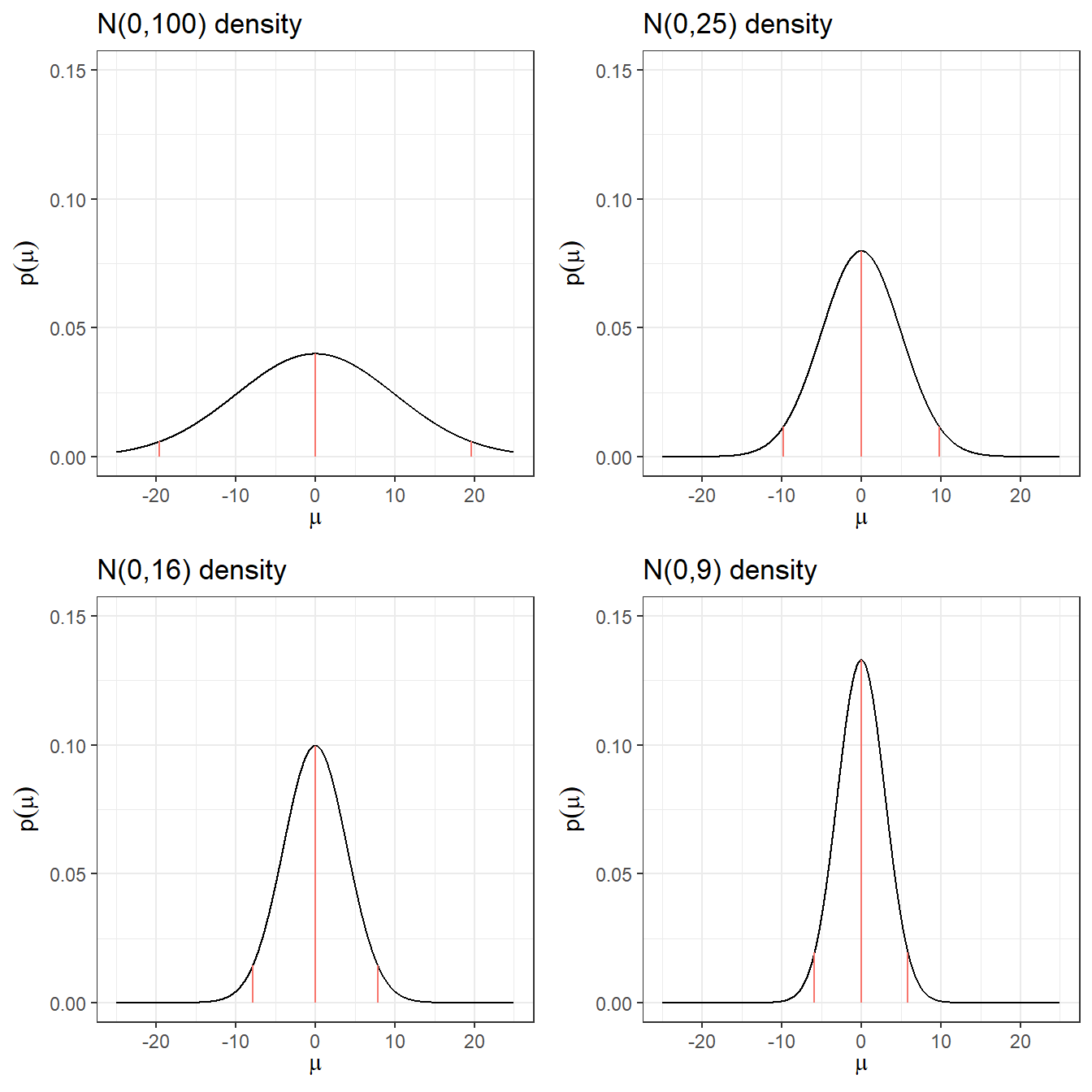
| Prior log(RR) | median log(RR) | q2.5 log(RR) | q97.5 log(RR) | q2.5 RR | q97. RR |
|---|---|---|---|---|---|
| N(0,100) | 0 | -19.6 | 19.6 | 0.0000000031 | 325098849.19 |
| N(0,25) | 0 | -9.8 | 9.8 | 0.0000554616 | 18030.5 |
| N(0,16) | 0 | -7.84 | 7.84 | 0.0003937258 | 2539.84 |
| N(0,9) | 0 | -5.88 | 5.88 | 0.0027950873 | 357.77 |
| N(0,4) | 0 | -3.92 | 3.92 | 0.019842524 | 50.4 |
| N(0,1) | 0 | -1.96 | 1.96 | 0.1408634941 | 7.1 |
Quick Summary
- Posterior could land on implausible values with small numbers of deaths in one group or other.
- These issues resolve somewhat with larger data sets
- With a precise likelihood (e.g., large sample size or large number of events), data rescues you from allowing implausible values.
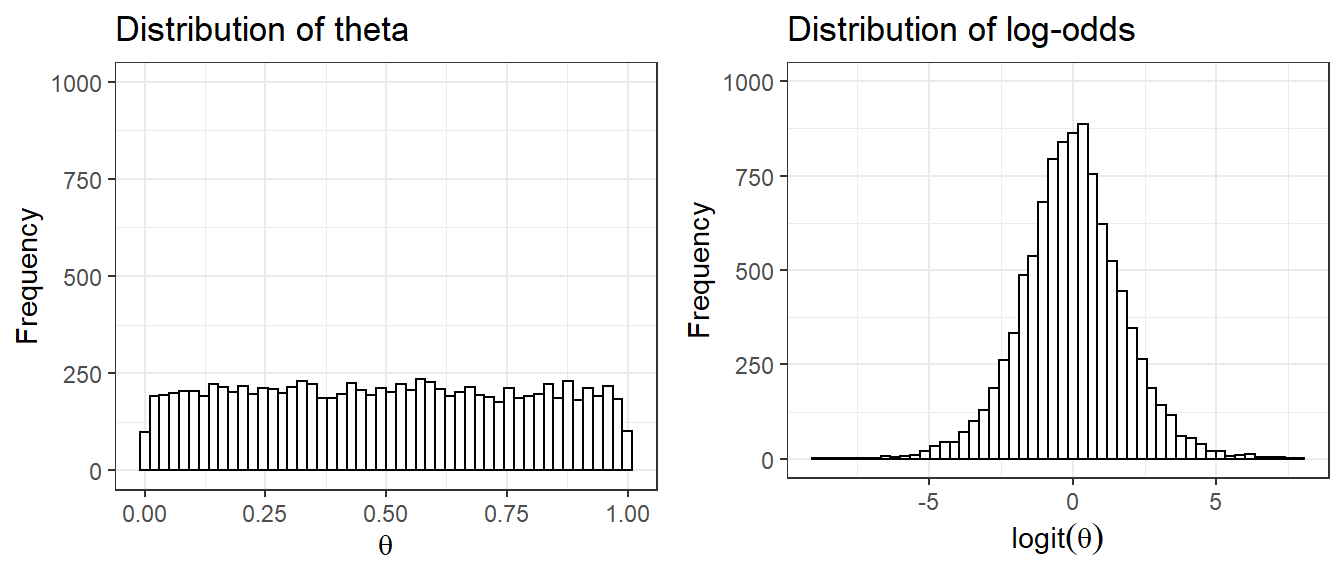
1. ISSUE with Uniform Priors uniform priors on one scale are not uniform on a transformed scale
Suppose we set prior \(\theta \sim U(0,1)\) as an uninformative prior on the parameter quantifying risk of adverse event, probability \(\theta\)
- Prior distribution on log(\(\frac{\theta}{1-\theta}\)), which is also called the logit of \(\theta\) is no longer uniformly distributed
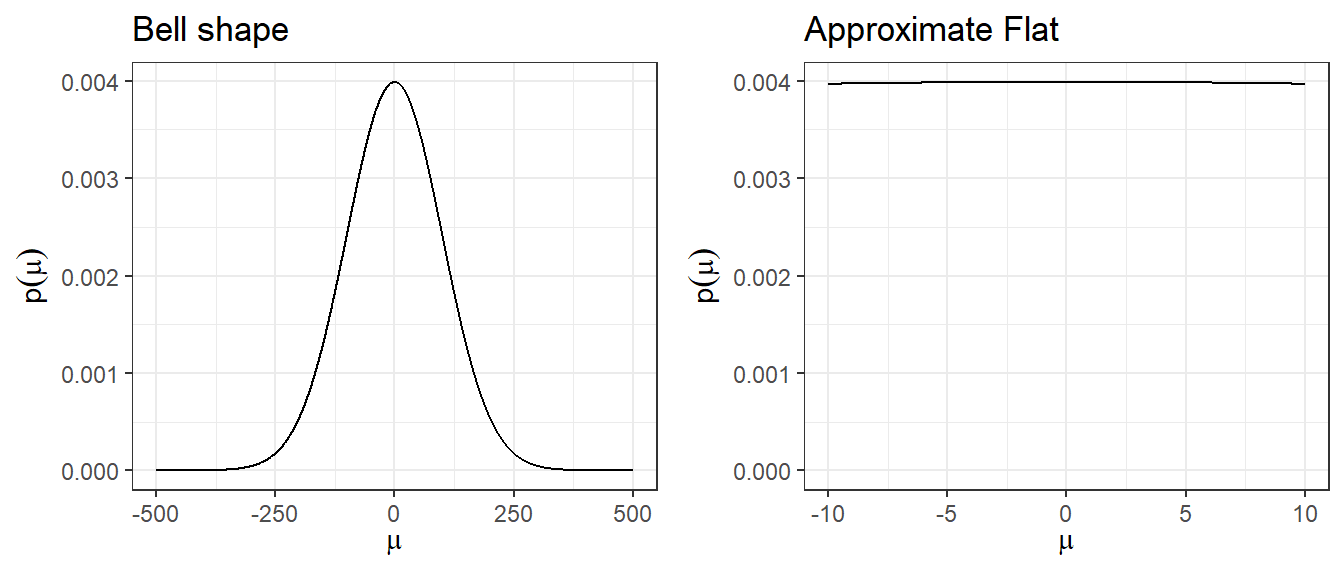
2. Using large variance normal distribution as non-informative prior
- How is a normal distribution N(0,\(100^2\)), with its bell-shape, uninformative?
- It does not put equal density on all points, as the density drops off from zero in each direction
- The key is that it is locally uniform
- In the region where a parameter is likely to lie, the normal distribution is flat.
4.2.2 Minimally informative prior
- Use substantive knowledge to put most prior weight on possible values, without being too restrictive
From example, a RR for mortality in a trial, a prior with most weight on values of 0.66 to 1.5, a N(0,1) prior would be considered suitable.
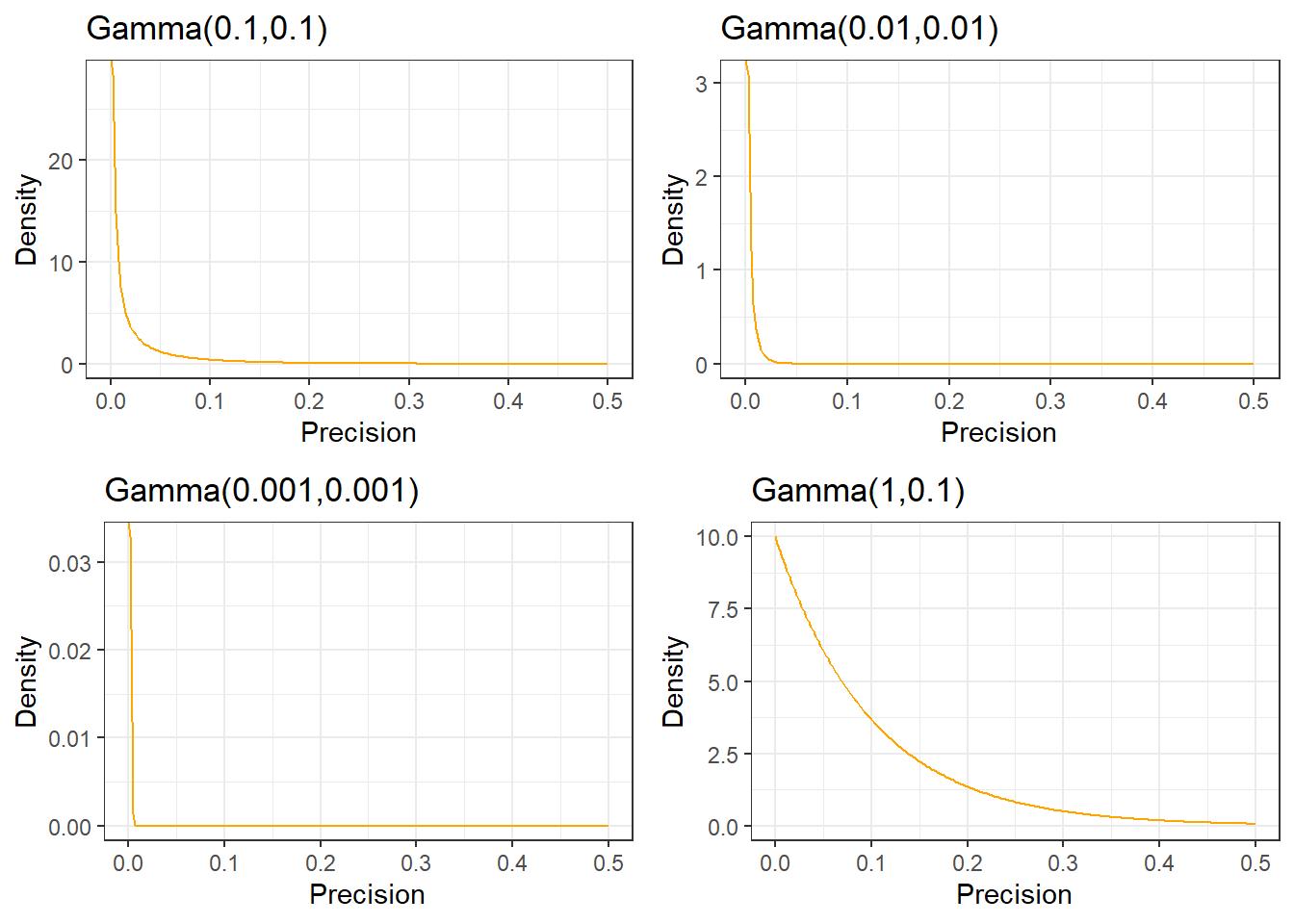
For the between-person standard deviation of a 0-40 quality of life instrument, a prior with most weight on values under 10, a possible prior would be Gamma(0.1,0.1) on the precision.
4.2.3 Skeptical Prior
priors that express doubts about large effects
Mathematically speaking, a sceptical prior about a treatment effect will have a mean of zero and a shape chosen to include plausible treatment differences which determines the degree of scepticism.
- This is centred at no effect and a 95% CR extends to a minimally clinically important difference (MCID)
Skeptical prior will “shrink” back observed results towards the null effect
If under the skeptical prior, the posterior results support conclusion of effectiveness (results suggest departure from null), the skeptic is convinced!
Spiegelhater suggested a reasonable degree of scepticism maybe feeling that the study has been designed around an alternative hypothesis that is optimistic,
- formalized by a prior with only a small probability say 5% that the effect is as large as the optimistic alternative
Example from EOLIA trial(Goligher et al. 2018)
- MCID for 60-day mortality in RR comparing between ECMO and Rescue Lung Injury in Severe ARDS is 0.67, log(0.4/0.6) = -0.405.
- 0 (null, RR=1) will be the mean of the skeptical prior!
- Let P(RR<0.67) = P(log(RR)< -0.405) = 0.05, that is saying the probability of the ECOMO being effective beyond MCID is only 5%.
- Employee z transformation on normal distribution, we have
\[ P(log(RR)< -0.405) = P(\frac{log(RR)-0}{\sigma} < \frac{(-0.405) - 0}{\sigma}) = P(z < \frac{-0.405}{\sigma}) =0.05\]
\[ qnorm(0.05,0,1) \times \sigma = -0.405 \] \[\sigma = \frac{0.405}{qnorm(0.05,0,1)} = 0.246\]
- yielding a candidate skeptical prior on log(RR) ~ \(N(0,0.246^2)\)
4.2.4 Optimistic/enthusiastic Prior
- This is centred at the MCID and a 95% CR extends to no effect
- Optimistic Prior will move observed results towards the MCID
- If a optimist is convinced that there is no effect, the evidence for no effect is strong
- Spiegelhater suggested an “enthusiastic” prior centred on the althernative hypothesis (meeting MCID) and with a low chance (say 5% probability) that the true treatment benefit is negative!
Example from EOLIA trial(Goligher et al. 2018)
MCID for 60-day mortality in RR comparing between ECOMO and Rescue Lung Injury in Severe ARDS is 0.67, log(0.4/0.6) = -0.405.
-0.405 will be the mean of the enthusiastic prior!
Let P(RR>1) = P(log(RR)> 0) = 0.05, that is saying the probability of the ECMO not being effective is 5%.
Employee z transformation on normal distribution, we have
\[ P(log(RR)> 0) = P(\frac{log(RR)-(-0.405)}{\sigma}> \frac{0-(-0.405)}{\sigma}) = P(z > \frac{0.405}{\sigma}) =0.05\] \[P(z < \frac{0.405}{\sigma}) = 1- 0.05 = 0.95\] \[qnorm(0.95,0,1) \times \sigma = 0.405\] \[\sigma = \frac{0.405}{qnorm(0.95,0,1)} = 0.246\]
- yielding a candidate enthusiastic prior on log(RR) ~ \(N(-0.405,0.246^2)\)
4.2.5 Evaluating Priors?
- Section 5.8 (David J. Spiegelhalter, Abrams, and Myles 2003) introduced a Box approach to comparing priors with subsequent data in assessing the ability of the chosen subjective prior to predict the true benefit of intervention
- The prior is used to derive a predictive distribution for future observations, and thus to calculate the chance of a result with lower predictive ordinate than that actually observed:
- when the predictive distribution is symmetric and unimodal, this is analagous to a traditional two-sided P-value in measuring the predictive probability of getting a result at least as extreme as that observed.
- this assessment can be used to evaluate prior distributions parameter values
- When we have several candidate prior distributions (e.g. lognormal, beta, normal, etc), we can use goodness-of-fit statistics like Kolmogorov-Smirnov, Cramer-von Mises, and Anderson-Darl to evaluate which distribution best fit the prior belief density.
4.3 Historical data (meta-analysis)
- Incorporating historical data in Bayesian analysis
- these can be formalized as a means of using past evidence as a basis for a prior distribution for a parameter of interest
- Additional reading: Section 5.4 Summary of External Evidence of (David J. Spiegelhalter, Abrams, and Myles 2003)
- Meta-analysis is a very useful tool for evidence synthesis in clinical research
- Juan Pablo will give us a guest lecture on Bayesian meta-analysis after reading week!
- We can directly use published meta-analysis results to construct priors
- if not available, one can also complete a meta-analysis to synthesis evidence for prior construction
- These types of prior are called data-derived priors.
- For example, in the Bayesian reanalysis of the EOLIA trial, data-derived priors are constructed from a Bayesian meta-analysis of published relevant studies.
- The posterior distribution (updated belief) of treatment effect is produced by combining data-derived prior with data from the current study.
Downweighting:
To reflect concerns about possible differences between the current and previous studies, the variance of the past studies can be inflated to receive less weight in the analysis on the pooled estimate of effect.
Data-derived prior from the Bayesian reanalysis of the EOLIA trial(Goligher et al. 2018)
- Data-derived prior was developed based on three relevant studies from a meta-analysis of ECMO for ARDS (Munshi et al. 2014)
- Three studies are:(Peek et al. 2009), (Pham et al. 2013), and (Noah et al. 2011)
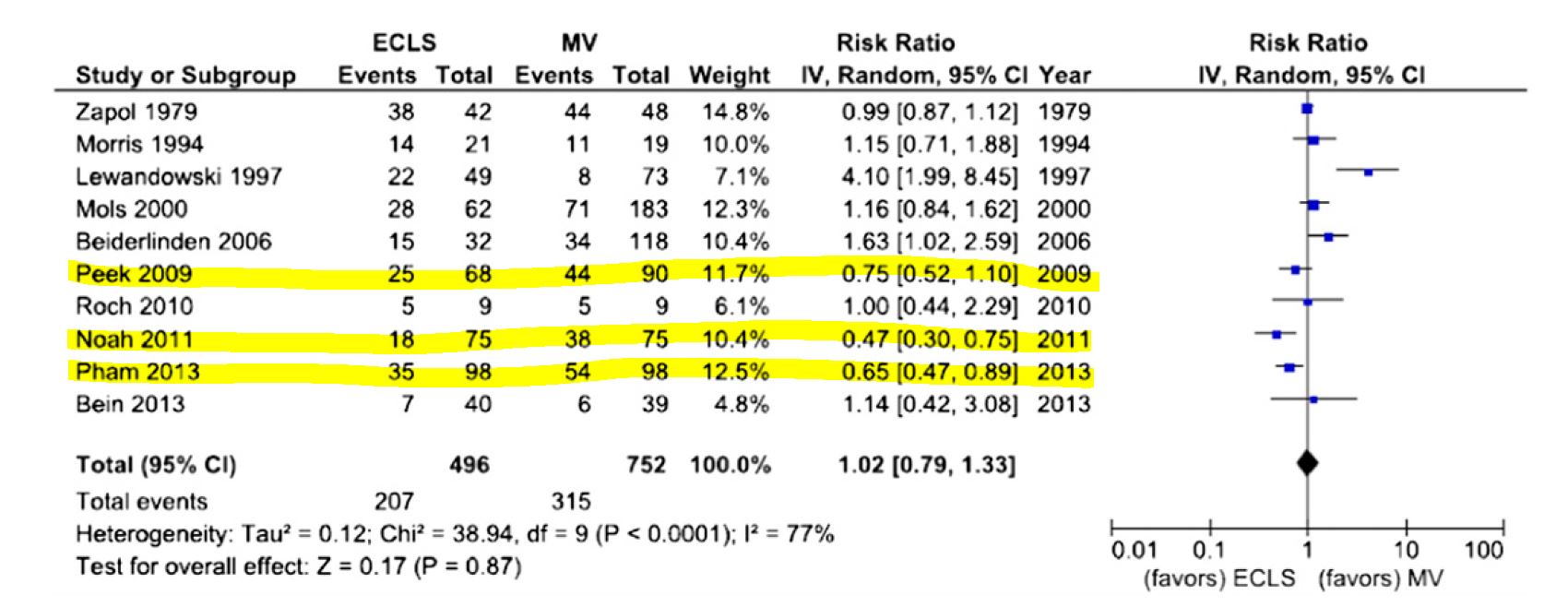
Figure 4.1: In-hospital mortality. Forest plot showing pooled analysis of four randomized controlled trials and six observational studies comparing extracorporeal life support (ECLS) to conventional mechanical ventilation (MV) from Munshi et al 2014.
- After fitting a random effect model, the pooled RR is estimated as 0.64 with 95% CI (0.38 - 1.06).
- We now express this prior as a normal likelihood on the log(RR) scale and consider three scenarios of “downweighting” (10%, 50% and 100%).
CI.normal <- log(c(0.38, 1.06))
sigma <- (CI.normal[2] - CI.normal[1])/(2*1.96)
mu <- log(0.64)
xlabs <- c(0.2, 0.4, 0.6, 0.8, 1, 3)
noweight <- dnorm(log(seq(0.1,3, length=201)), mu, sigma)
weight50 <- dnorm(log(seq(0.1,3, length=201)), mu, sigma/sqrt(0.5))
weight10 <- dnorm(log(seq(0.1,3, length=201)), mu, sigma/sqrt(0.1))
d <- data.frame(logrr.range = rep(log(seq(0.1,3, length=201)),3),
plog.rr = c(noweight, weight50, weight10),
Weighting = rep(c("100% weight","50% weight","10% weight"),each=201))
ggplot(d, aes(logrr.range, plog.rr,colour=Weighting))+
geom_line(size = 1)+
xlab("RR")+
ylab("probability density")+
ylim(c(0,2))+
scale_x_continuous(breaks = log(xlabs),labels=xlabs, limits=c(log(0.1), log(3)))+
scale_colour_manual(values=c("goldenrod","steelblue","black"))+
theme_bw()+
ggtitle("Data-derived priors")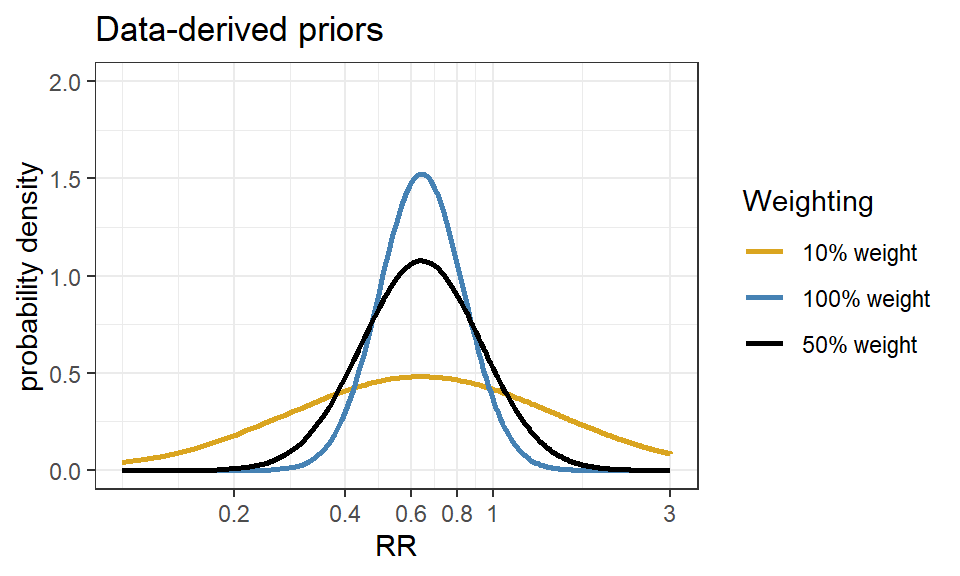
4.4 Hierarchical priors and shrinkage priors
- Don’t necessarily have information about the value of a parameter
- Expresses knowledge, for example, that a several of parameters, \(\mu_1, \ldots, \mu_k\) have a common mean, without saying what that mean is
\[\mu_i \sim N(\mu_0, \sigma^2) \]
The Bayesian posterior means for \(\mu_i\) will be “shrunk” towards the overall mean \(\mu_0\) - (this is called formally as exchangeability)
By sharing information this way, individual estimates have smaller variances - A way of avoiding overfitting
These are priors on higher level parameters (variances and random effects are the most common)
Example prior distribution for variance - Gamma Distribution
Shrinkage priors in Bayesian penalization aim to shrink small effects to zero while maintaining true large effects.
The horseshoe prior is a member of the family of multivariate scale mixtures of normals, and is therefore closely related to widely used approaches for sparse Bayesian learning, including, among others, Laplace priors (e.g. the LASSO) and Student-t priors.
Example horseshoe prior
- Consider a linear regression model with covariates \(X = (x_1, \ldots, x_p)\). \(\beta\) is a \(1\times p\) vector of regression coefficient and i index number of subject.
\[y_i = \beta^TX_i + \epsilon_i, \ e_i \sim N(0,\sigma^2), \ i = 1, \ldots, n\]
The horseshoe prior (hierarchical) is given as: \[\beta_j \mid \lambda_j, \tau, \sim N(0, \lambda_j^2 \tau^2)\] \[\lambda_j \sim halfCauchy(0,1), j = 1, \ldots, p.\] \[\tau \sim halfCauchy(0,\tau_0)\]
\(\lambda_j\) is called local shrinkage parameter - enable some \(\beta\) to escape the shrinkage
\(\tau\) is the global shrinkage parameter - shrink all \(\beta\) towards zero, thus removing the corresponding covariate from the regression model.
# Visually compare normal, student_t, cauchy, laplace, and product_normal
compare_priors <- function(scale = 1, df_t = 2, xlim = c(-10, 10)) {
dt_loc_scale <- function(x, df, location, scale) {
1/scale * dt((x - location)/scale, df)
}
dlaplace <- function(x, location, scale) {
0.5 / scale * exp(-abs(x - location) / scale)
}
dproduct_normal <- function(x, scale) {
besselK(abs(x) / scale ^ 2, nu = 0) / (scale ^ 2 * pi)
}
stat_dist <- function(dist, ...) {
ggplot2::stat_function(ggplot2::aes_(color = dist), ...)
}
ggplot2::ggplot(data.frame(x = xlim), ggplot2::aes(x)) +
stat_dist("normal", size = .75, fun = dnorm,
args = list(mean = 0, sd = scale)) +
stat_dist("student_t", size = .75, fun = dt_loc_scale,
args = list(df = df_t, location = 0, scale = scale)) +
stat_dist("cauchy", size = .75, linetype = 2, fun = dcauchy,
args = list(location = 0, scale = scale)) +
stat_dist("laplace", size = .75, linetype = 2, fun = dlaplace,
args = list(location = 0, scale = scale)) +
stat_dist("product_normal", size = .75, linetype = 2, fun = dproduct_normal,args = list(scale = 1))+theme_bw()
}
# Cauchy has fattest tails, followed by student_t, laplace, and normal
compare_priors()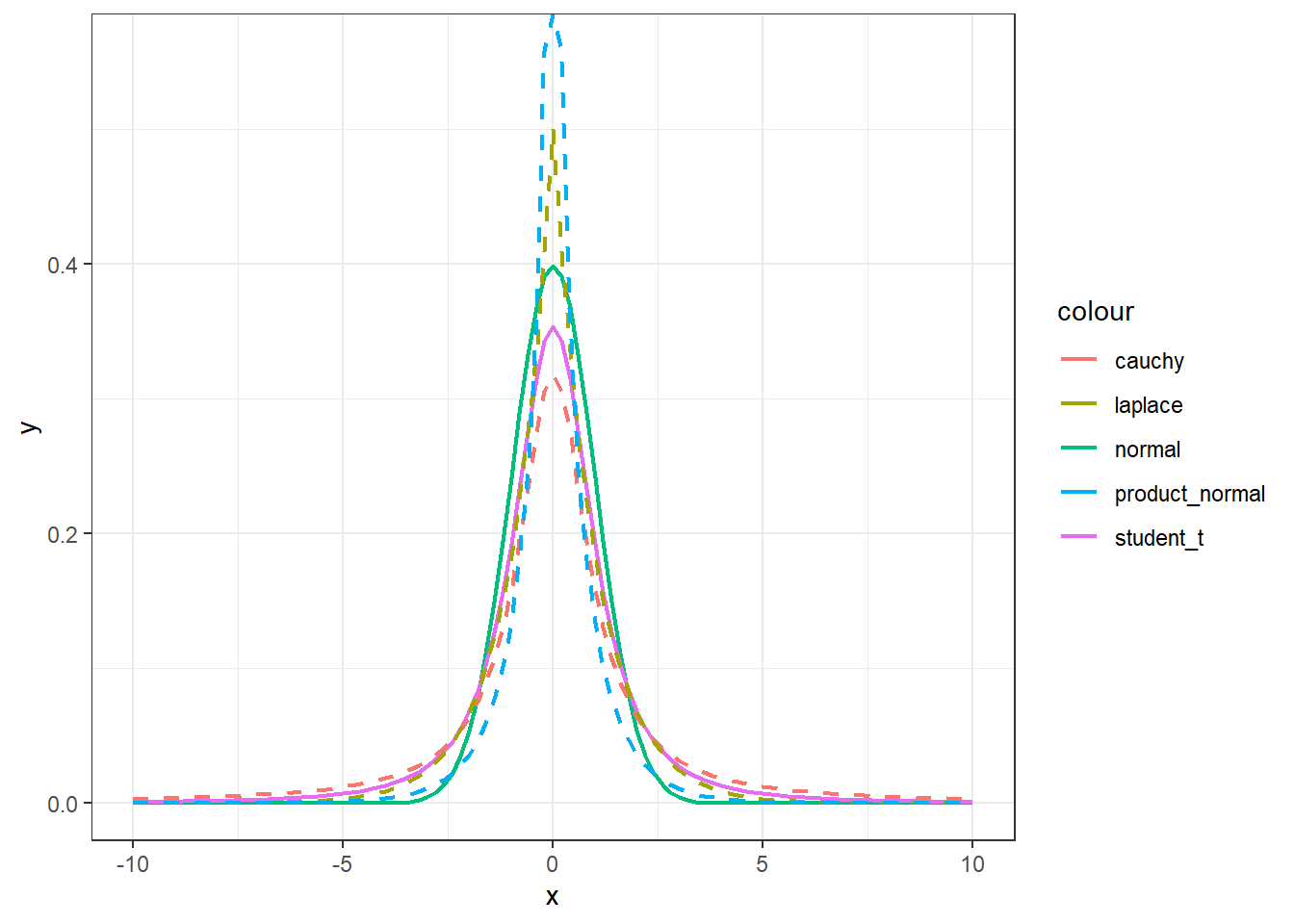
R Session information
## R version 4.1.3 (2022-03-10)
## Platform: x86_64-w64-mingw32/x64 (64-bit)
## Running under: Windows 10 x64 (build 19044)
##
## Matrix products:
##
## locale:
## [1] LC_COLLATE=English_Canada.1252 LC_CTYPE=English_Canada.1252
## [3] LC_MONETARY=English_Canada.1252 LC_NUMERIC=C
## [5] LC_TIME=English_Canada.1252
##
## attached base packages:
## [1] grid stats graphics grDevices utils datasets methods
## [8] base
##
## other attached packages:
## [1] extraDistr_1.9.1 MCMCpack_1.6-1 MASS_7.3-55
## [4] coda_0.19-4 SHELF_1.8.0 bayesplot_1.9.0
## [7] ggmcmc_1.5.1.1 tidyr_1.2.0 ggpubr_0.4.0
## [10] tweenr_1.0.2 gganimate_1.0.7 VennDiagram_1.7.1
## [13] futile.logger_1.4.3 truncnorm_1.0-8 brms_2.16.3
## [16] Rcpp_1.0.8.3 dplyr_1.0.8 ggplot2_3.3.5