My first class on Bayesian inference - Conjugate prior
Learning Objectives
Learn two simple Bayesian models (Beta-binomial & normal-normal)
Discuss practical advantages and disadvantages of Bayesian approach
1. Introduction to Bayesian approach
The Bayesian approach to parameter estimation is based on Bayes’ theorem.
Let \(\theta\) be the parameter of interest and \(y\) be the observed data.
\[\begin{aligned}
P(\theta \mid y) & = \frac{P(y \mid \theta)P(\theta)}{P(y)} \\
& = \frac{\text{likelihood of the data given the parameter} \times \text{prior}}{\text{marginal distribution of the data}} \\
& \propto \text{likelihood}(y \mid \theta ) \times \text{prior}(\theta)
\end{aligned}\]
\(P(y)\) is called a normalizing constant. It ensures that \(\int P(\theta \mid y)\, d\theta = 1\), so that the posterior distribution is a proper probability distribution.
Its numerical value is usually not of direct interest, unless we are comparing different models for the data.
The key idea in Bayes’ theorem is that the posterior distribution is proportional to the likelihood times the prior: \[P(\theta \mid y) \propto P(y\mid \theta)P(\theta).\]
Likelihood vs probability distribution
Probability distribution: a function of the data when the parameter is fixed.
A probability distribution \(f(y\mid \theta)\) sums or integrates to 1 over all possible values of the random variable \(Y\), with \(\theta\) treated as fixed.
It answers the question: “If the parameter were \(\theta\), how likely is each possible outcome \(y\)?”
Likelihood: the same mathematical expression, but viewed as a function of the parameter when the observed data are fixed.
The likelihood function is written as \(L(\theta \mid y_{obs}) \propto f(y_{obs}\mid \theta)\).
It answers the question: “Given the observed data \(y_{obs}\), which values of \(\theta\) are more plausible?”
A likelihood does not need to integrate to 1 over \(\theta\). In the likelihood, the data are fixed and \(\theta\) varies.
Bayes’ Rule
The ELISA test for HIV was widely used in the mid-1990s for screening blood donations. Like most medical diagnostic tests, ELISA is not perfect.
If a person truly carries the HIV virus, experts estimated that the test gives a positive result 97.7% of the time. This is the sensitivity of the test.
If a person does not carry the HIV virus, ELISA gives a negative result 92.6% of the time. This is the specificity of the test.
Suppose the HIV prevalence in the population at that time was 0.5%. This is the prior base rate.
Now suppose a randomly selected individual tests positive. We want the conditional probability that the person truly carries HIV.
We know the probability of a positive test if HIV is truly present: \[P(T^+ \mid D^+) = 0.977,\]
and the probability of a positive test if HIV is not present: \[P(T^+ \mid D^-) = 1 - 0.926 = 0.074.\]
Using Bayes’ rule, we can obtain the posterior probability of disease given a positive test result:
Therefore, the posterior distribution is also beta:
\[ \theta \mid x \sim Beta(\alpha+x,\beta+n-x). \]
In words, compared with the prior:
\(\alpha\) is updated to \(\alpha+x\)
\(\beta\) is updated to \(\beta+(n-x)\)
So the data contribute the observed number of events and non-events directly to the posterior.
The prior and posterior are both beta distributions, which is why the beta prior is called a conjugate prior for the binomial model.
Interpretation of a beta prior
Suppose we start with a beta prior with very small parameters:
\[ \theta \sim Beta(0.001, 0.001). \]
After observing \(x\) events in \(n\) trials, the posterior is
\[ \theta \mid x \sim Beta(0.001+x, 0.001+n-x). \]
When the prior is very weak and the sample size is reasonably large, the posterior mean is close to
\[ \frac{x}{n}, \]
which is the sample proportion and also the maximum likelihood estimate.
A useful heuristic for interpreting the \(Beta(\alpha,\beta)\) prior is:
\(\alpha\) and \(\beta\) can be viewed as prior pseudo-counts
\(\alpha+\beta\) represents the strength of the prior information
the prior mean is \[\frac{\alpha}{\alpha+\beta}\]
This interpretation is a helpful approximation for teaching, not a literal statement that the prior came from actual observed data.
Working example of Beta-binomail model
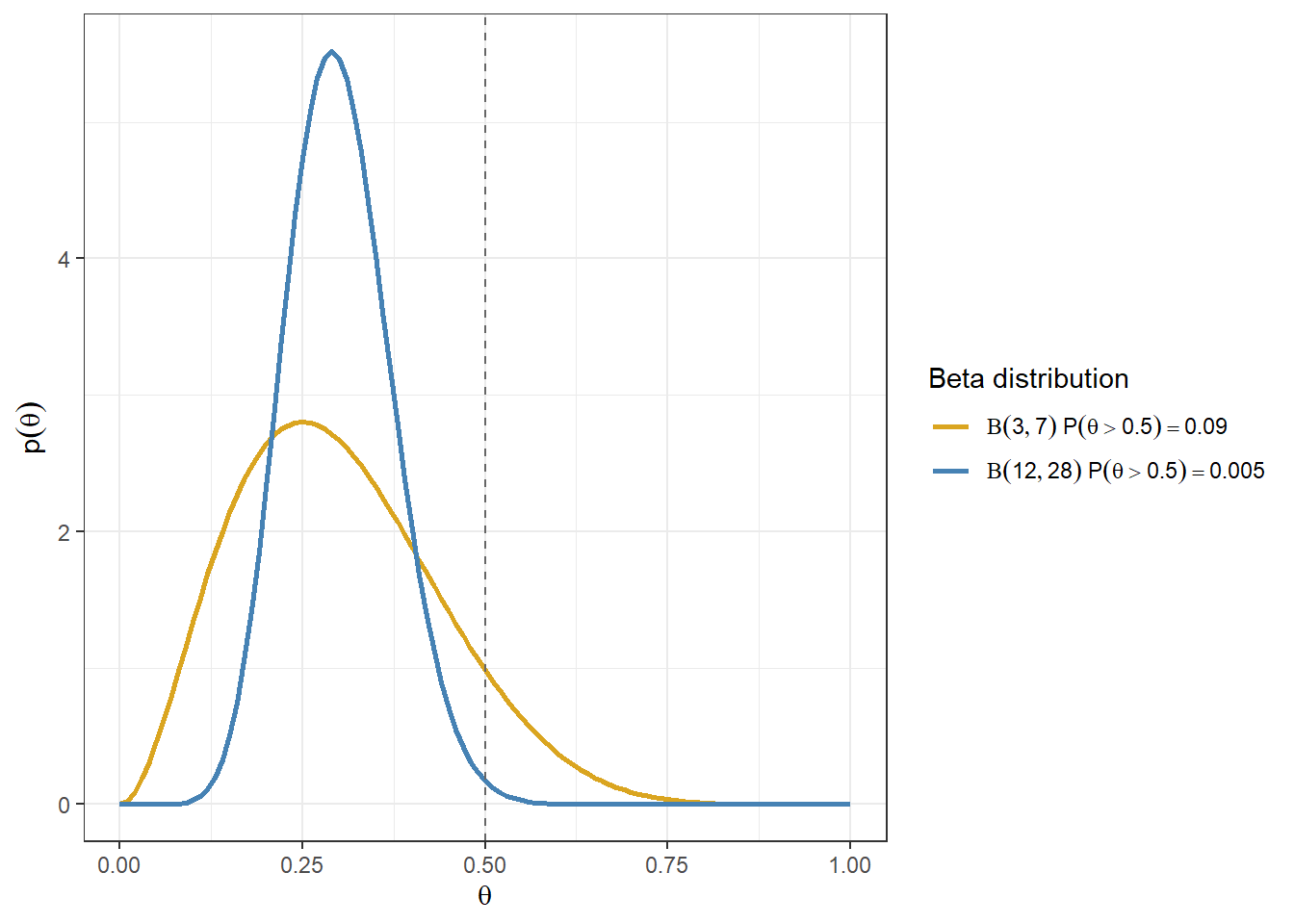
Consider the priors \(Beta(3,7)\) and \(Beta(12,28)\).
The gold line corresponds to a prior with mean \(3/(3+7)=0.3\).
The blue line corresponds to a prior with mean \(12/(12+28)=0.3\).
Although these two priors have the same mean, they have different spreads. The prior with larger \(\alpha+\beta\) is more concentrated, so it reflects stronger prior information.
For example, the amount of prior mass above a cutoff such as 0.5 can differ even when the two priors have the same mean.
Code
d <-tibble(theta =seq(from =0, to =1, length.out =101)) %>%expand(theta, a =c(3, 12), b =c(7,28)) %>%mutate(PriorSet =paste0("Beta(",format(a), "," , format(b),")")) %>%mutate(priorDensity =dbeta(theta, shape1 = a,shape2 = b))%>%filter(a/(a+b)==0.3)# Compute P(theta > 0.5) for each priorprob_table <- d %>%distinct(a, b, PriorSet) %>%mutate(prob_gt_05 =pbeta(0.5, shape1 = a, shape2 = b, lower.tail =FALSE),label =paste0(PriorSet, "~P(theta>0.5)==", round(prob_gt_05, 3)))# Merge labels back for plottingd <- d %>%left_join(prob_table %>%select(PriorSet, label), by ="PriorSet")ggplot(d, aes(theta, priorDensity, colour = label)) +geom_line(size =1) +geom_vline(xintercept =0.5, linetype ="dashed", colour ="grey40") +xlab(expression(theta)) +ylab(expression(p(theta))) +theme(legend.position ="bottom") +scale_colour_manual(values =c("goldenrod", "steelblue"),labels = scales::label_parse(),name ="Beta distribution") +theme_bw()
Summarizing the posterior distribution
Because we know the posterior distribution in closed form, we can easily calculate quantities such as:
the posterior mean: \[E(\theta \mid x) = \frac{\alpha+x}{\alpha+\beta+n}\]
95% credible intervals
posterior probabilities such as \(P(\theta < 0.2)\), \(P(\theta > 0.5)\), or \(P(0.4 < \theta < 0.6)\)
These can be used to make direct probability statements about \(\theta\) under the assumed model and prior. For example, we may say that the posterior probability that the adverse event rate is below 0.2 is 0.95.
We can also generate informative plots to compare priors and posteriors. All of this can be done easily in R.
Interpreting posterior probability
Useful interpretations of posterior probabilities in Bayesian clinical analyses. These thresholds are context-dependent and should be pre-specified when used for decision-making.
Posterior Probability
Verbal Interpretation
Common Usage in Bayesian Clinical Analysis
< 0.05
Very unlikely
Strong evidence against the event or effect
0.05 - 0.20
Unlikely
Little support for the hypothesis
0.20 - 0.40
Somewhat unlikely
Weak evidence; insufficient for a positive conclusion
0.40 - 0.60
Uncertain / Equipoise
Little evidence in either direction
0.60 - 0.80
Somewhat likely
Modest evidence in favour
0.80 - 0.90
Likely
Reasonable evidence; often used in early-phase decisions
0.90 - 0.95
Very likely
Strong evidence
0.95 - 0.99
Highly probable
Very strong evidence
> 0.99
Virtually certain
Near-conclusive evidence
Data overwhelming the prior
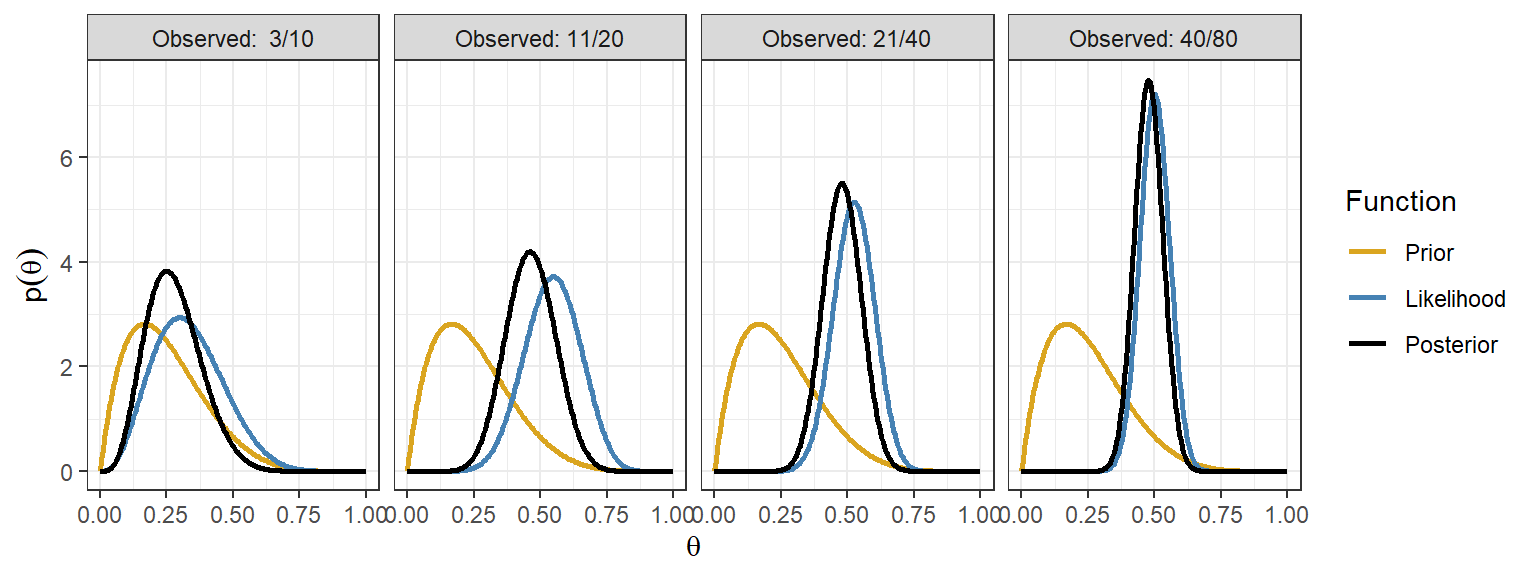
In the beta-binomial model, after observing \(x\) events in \(n\) trials, the posterior is
\[ \theta \mid x \sim Beta(\alpha + x, \beta + n - x), \]
Again, the posterior mean is a weighted average of the prior mean and the sample mean.
As the sample size increases, the weight on the prior decreases and the data increasingly dominate the posterior.
Use of the normal-normal model in clinical applications
In many clinical applications, we are interested in a parameter such as a mean difference, log-hazard ratio, log-odds ratio, or log-relative risk.
Suppose we have an estimate of the parameter, and call that estimate \(y\). Let \(\hat{\sigma}_y^2\) be its estimated variance.
We can treat this estimate as a single summary datum whose sampling distribution depends on the true parameter \(\theta\).
In large samples, it is often reasonable to use the approximation
\[ y \mid \theta \sim N(\theta,\sigma_y^2), \]
where \(\theta\) is the true parameter value and \(\sigma_y^2\) is the sampling variance of the estimator.
In practice, we usually replace \(\sigma_y\) by the reported standard error \(\hat{\sigma}_y\).
If a 95% confidence interval is reported as
\[ y \pm 1.96\hat{\sigma}_y, \]
then we can recover the standard error from the width of the interval.
This gives us a normal likelihood for \(\theta\) based on the published estimate and its standard error.
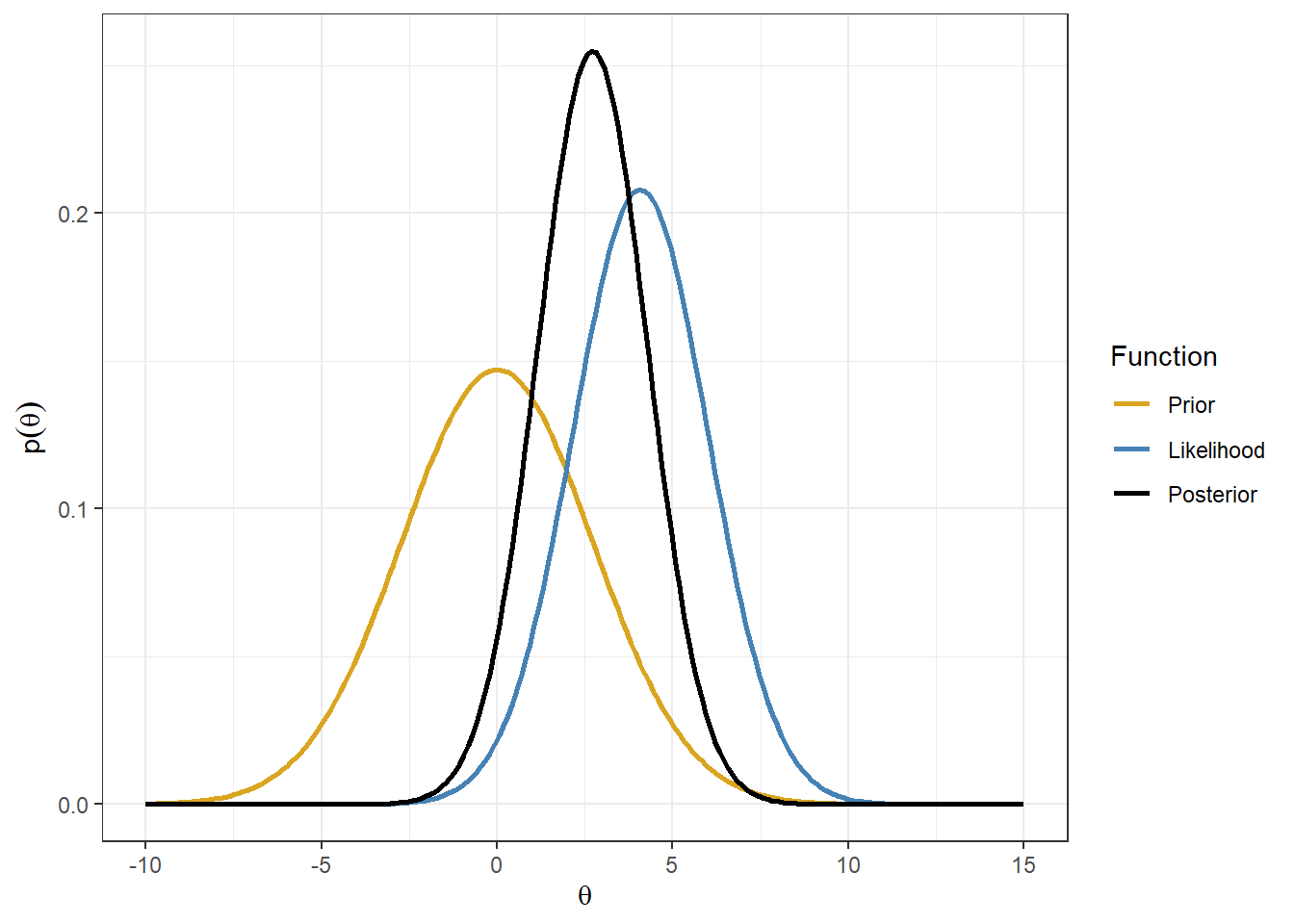
Working example - Treatment effect estimate on the mean
In this example, we simulate data for a small randomized study with \(n=100\) subjects, where 50% are assigned to control and 50% to treatment.
We then fit a linear regression model to estimate the treatment effect \(\theta\) on the outcome.
Code
n <-100set.seed(1234)treat <-1*(runif(n, min =0, max =1)<0.5)y <-5*treat+rnorm(n, mean =0, sd =10)fit<-lm(y~treat)summary(fit)
Call:
lm(formula = y ~ treat)
Residuals:
Min 1Q Median 3Q Max
-19.8662 -6.7095 -0.5731 5.7503 24.1866
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.303 1.423 0.916 0.3618
treat 4.080 1.918 2.127 0.0359 *
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 9.543 on 98 degrees of freedom
Multiple R-squared: 0.04414, Adjusted R-squared: 0.03438
F-statistic: 4.525 on 1 and 98 DF, p-value: 0.03591
Code
round(confint.default(fit, 'treat', level=0.95),3) # based on asymptotic normality
2.5 % 97.5 %
treat 0.321 7.84
Suppose the regression output gives an estimated treatment effect of 4.08 with standard error 1.918.
We will treat this reported estimate as our observed summary datum \(y\).
Using the large-sample approximation, we assume
\[ y \mid \theta \sim N(\theta,1.918^2). \]
Here, 1.918 is the observed standard error of the estimate, and we use it as the standard deviation of the sampling distribution.
Recall that the standard deviation of the sampling distribution of an estimator is its standard error.
If the standard error is not reported, but a 95% confidence interval is available, we can recover it from the interval width. For example, if the 95% confidence interval for \(y\) is \((0.321, 7.84)\), then
Working example - Bayesian reanalysis of an RCT: odds ratio
(Frequentist trial) Effect of a Resuscitation Strategy Targeting Peripheral Perfusion Status vs Serum Lactate Levels on 28-Day Mortality Among Patients With Septic Shock: The ANDROMEDA-SHOCK Randomized Clinical Trial(Hernández et al. 2019)
(Bayesian reanalysis) Effects of a Resuscitation Strategy Targeting Peripheral Perfusion Status versus Serum Lactate Levels among Patients with Septic Shock: A Bayesian Reanalysis of the ANDROMEDA-SHOCK Trial(Zampieri et al. 2020)
We are interested in making inference about the odds ratio (OR) for 28-day mortality comparing peripheral perfusion-targeted resuscitation with lactate-targeted resuscitation.
This section presents two versions of the Bayesian analysis:
a simple teaching example using the crude 2x2 odds ratio from the published counts; and
an approximate reconstruction of Zampieri et al.’s neutral prior result using their comparable adjusted frequentist logistic model OR.
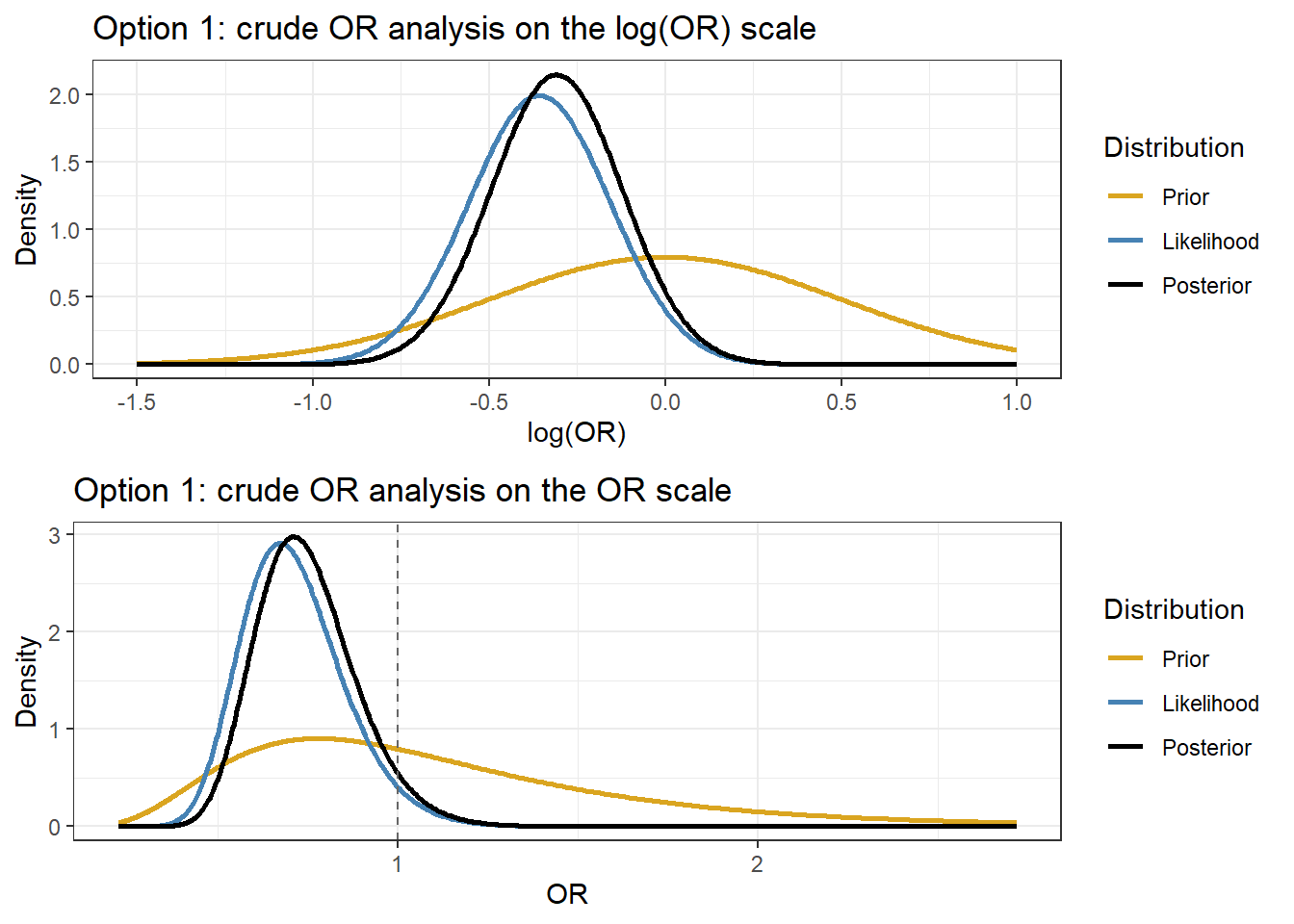
The first version is useful for illustrating Bayesian updating with a normal likelihood on the log(OR) scale.
The second version is included to show why the published posterior is more favorable than the crude 2x2 analysis.
\[
y \mid \theta \sim N(\theta, 0.2^2),
\qquad y=-0.358.
\]
Step 2: Neutral prior from Zampieri et al.
Zampieri et al. considered a neutral prior with mean 0 and standard deviation 0.5 on the log(OR) scale. We use the same prior here:
\[
\theta \sim N(0,0.5^2).
\]
This prior is centered at no effect because \(log(1)=0\). On the OR scale, it corresponds to a prior centered at \(OR=1\), while still allowing both benefit and harm.
Step 3: Posterior under the normal-normal model
Because both the prior and the likelihood are normal on the log(OR) scale, the posterior is also normal:
# Plot on both the log(OR) scale and the OR scaletheta_grid <-seq(-1.5, 1.0, length.out =400)or_grid <-exp(theta_grid)plot_log <-data.frame(x =rep(theta_grid, 3),density =c(dnorm(theta_grid, mean = mu0, sd = sd0),dnorm(theta_grid, mean = y_obs, sd = se_obs),dnorm(theta_grid, mean = mu1, sd = sd1) ),Distribution =factor(rep(c("Prior", "Likelihood", "Posterior"), each =length(theta_grid)),levels =c("Prior", "Likelihood", "Posterior") ))p1 <-ggplot(plot_log, aes(x, density, colour = Distribution)) +geom_line(linewidth =1) +xlab("log(OR)") +ylab("Density") +theme_bw() +scale_colour_manual(values =c("goldenrod", "steelblue", "black")) +ggtitle("Option 1: crude OR analysis on the log(OR) scale")plot_or <-data.frame(x =rep(or_grid, 3),density =c(dnorm(log(or_grid), mean = mu0, sd = sd0) / or_grid,dnorm(log(or_grid), mean = y_obs, sd = se_obs) / or_grid,dnorm(log(or_grid), mean = mu1, sd = sd1) / or_grid ),Distribution =factor(rep(c("Prior", "Likelihood", "Posterior"), each =length(or_grid)),levels =c("Prior", "Likelihood", "Posterior") ))p2 <-ggplot(plot_or, aes(x, density, colour = Distribution)) +geom_line(linewidth =1) +geom_vline(xintercept =1, linetype ="dashed", colour ="grey40") +xlab("OR") +ylab("Density") +theme_bw() +scale_colour_manual(values =c("goldenrod", "steelblue", "black")) +ggtitle("Option 1: crude OR analysis on the OR scale")ggarrange(p1, p2, nrow =2)
Second, approximate reconstruction of the published neutral prior result
Zampieri et al. did not use the crude OR above as their main Bayesian likelihood. Instead, they fit a Bayesian hierarchical logistic regression for 28-day mortality with adjustment for important baseline covariates and a random intercept for center.
To make a simpler approximation that is closer to their published result, we can use:
the same neutral prior, \[\theta \sim N(0,0.5^2),\]
but replace the crude OR with the comparable adjusted frequentist logistic-model OR reported in the paper.
For 28-day mortality, Zampieri et al. reported a comparable adjusted frequentist logistic-model result of
\[
OR = 0.61 \quad (95\%\, CI:\ 0.38,\ 0.92).
\]
We now use this adjusted OR and CI to define an approximate normal likelihood on the \(log(OR)\) scale.
This second analysis is included to mimic the published neutral prior posterior more closely. It still does not reproduce the paper exactly, because:
we do not have the full patient-level data in this worked example,
we are not fitting the hierarchical logistic regression directly,
and we are replacing the full regression likelihood by a normal approximation based on the published adjusted OR and CI.
Code
# Approximate reconstruction of Zampieri's neutral-prior result# using the published comparable adjusted logistic-model OR# published comparable adjusted frequentist logistic-model resultor_adj <-0.61ci_low <-0.38ci_high <-0.92# approximate likelihood on log(OR) scaley_obs2 <-log(or_adj)se_obs2 <- (log(ci_high) -log(ci_low)) / (2*1.96)# same neutral priormu0_2 <-0sd0_2 <-0.5prec0_2 <-1/ sd0_2^2# posteriorprec_y2 <-1/ se_obs2^2prec2 <- prec0_2 + prec_y2mu2 <- (prec0_2 * mu0_2 + prec_y2 * y_obs2) / prec2sd2 <-1/sqrt(prec2)cat("Adjusted OR used for approximation =", round(or_adj, 3), "\n")
Adjusted OR used for approximation = 0.61
Code
cat("Approximate SE on log scale =", round(se_obs2, 3), "\n")
Approximate SE on log scale = 0.226
Code
cat("Approximate posterior median OR =", round(exp(mu2), 3), "\n")
Approximate posterior median OR = 0.663
Code
cat("Approximate posterior 95% CrI for OR = (",round(exp(mu2 -1.96* sd2), 3), ", ",round(exp(mu2 +1.96* sd2), 3), ")\n", sep ="")
Approximate posterior 95% CrI for OR = (0.443, 0.992)
Code
# Posterior summaries for the approximate reconstructionres2 <-c(posterior_median_OR =exp(mu2),lower_95_CrI =exp(mu2 -1.96* sd2),upper_95_CrI =exp(mu2 +1.96* sd2),`Pr(OR < 1)`=pnorm(log(1), mean = mu2, sd = sd2),`Pr(OR < 0.8)`=pnorm(log(0.8), mean = mu2, sd = sd2))round(res2, 3)
Under the neutral prior, Zampieri et al. reported a posterior OR of approximately 0.65 (0.43, 0.96).
Summary of Conjugate priors & models
There are a small number of prior-likelihood pairs where the prior and the posterior are in the same family (e.g., both beta, both normal): these are called conjugate models
These posterior distributions can be computed without specialized software
These examples are useful for illustrating how Bayesian methods combine prior information with data
They have only limited practical usefulness - limits on types priors, limits on number of parameters
They are useful teaching tools, soon we will see how we can extend beyond these simple models
4. Bayesian vs Frequentist: A Tale of Two Designs
To make the comparison concrete, consider a simple two-arm randomized controlled trial comparing treatment versus control on a continuous outcome.
We assume:
The treatment effect of interest is \[\delta = \mu_T - \mu_C,\] the difference in mean outcome between the treatment and control groups.
The minimally clinically important difference (MCID) is \(\delta = 1\). This means a difference of 1 unit is the smallest effect that would be considered clinically meaningful.
The outcome standard deviation is assumed known and equal to \(\sigma = 2\) (variance \(=4\)).
Outcomes are normally distributed.
We will design the same trial in two different ways:
a frequentist design, based on controlling long-run error rates, and
a Bayesian design, based on posterior probabilities and a pre-specified decision rule.
The main questions are the same in both cases:
How many patients do we need?
What rule will we use to declare success?
How often will that rule lead to a correct or incorrect conclusion?
4.1 Frequentist Design
In a frequentist design, we choose the sample size so that the final analysis has acceptable long-run operating characteristics.
Here we specify:
Type I error: \(\alpha = 0.05\) (two-sided)
This means that if there is truly no treatment effect, the trial will incorrectly declare a difference about 5% of the time in the long run.
Power: \(1-\beta = 0.80\)
This means that if the true treatment effect is the MCID, the trial has an 80% chance of detecting it.
For a two-sample \(z\)-test with equal allocation, the required sample size per arm is
where \(z_{1-\alpha/2}=1.96\) and \(z_{1-\beta}=0.842\).
Code
# Frequentist sample sizedelta <-1# MCIDsigma <-2# SDalpha <-0.05# Type I errorpower <-0.80# Powerz_alpha <-qnorm(1- alpha/2)z_beta <-qnorm(power)n_per_arm <-ceiling(2* sigma^2* (z_alpha + z_beta)^2/ delta^2)n_total <-2* n_per_armcat("Required n per arm:", n_per_arm, "\n")
Required n per arm: 63
Code
cat("Required total n: ", n_total, "\n")
Required total n: 126
What the frequentist design gives you:
A fixed sample size chosen before the trial starts
A decision rule: reject \(H_0: \delta = 0\) if \(p < 0.05\)
A long-run guarantee on error rates: under repeated use of this design, the false positive rate is controlled at 5%
What it cannot give you: - A probability statement such as \(P(\delta > 1 \mid \text{data})\), the probability the treatment is clinically meaningful given what you observed.
4.2 Bayesian Trial Design
A Bayesian trial design answers the same practical questions as a frequentist design, but it does so in a different way.
We still need to decide:
How to model the data
What prior information to use
What rule will count as a successful trial
How often that rule leads to the right or wrong conclusion
The main difference is that a Bayesian design is built around the posterior distribution of the treatment effect after seeing the data.
So in this setting, the data can be summarized by the observed mean difference \(d\), and the uncertainty around \(d\) decreases as the sample size increases.
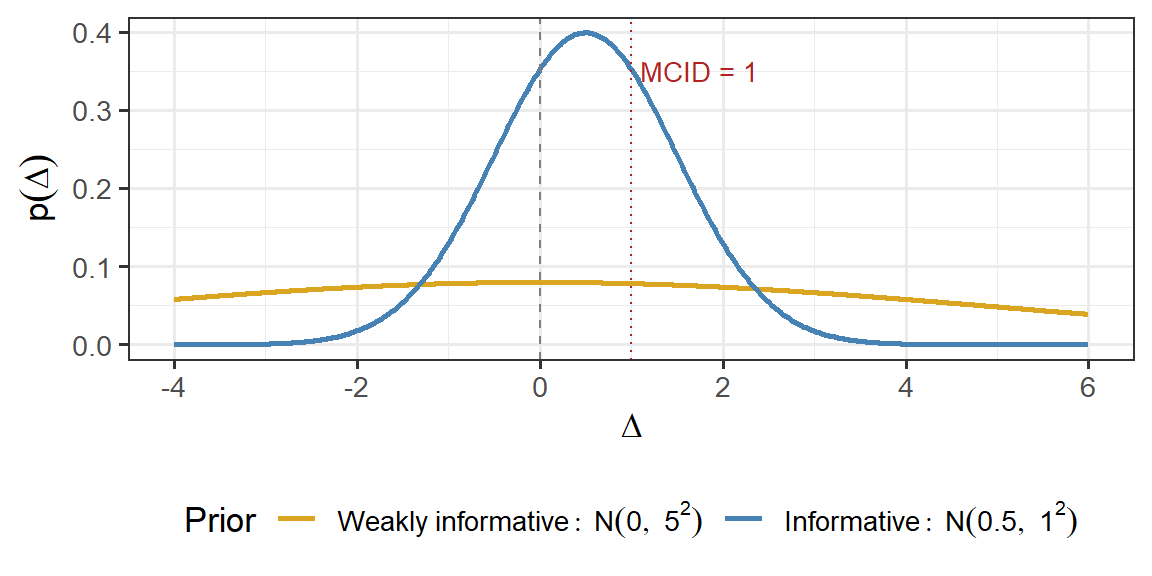
Prior
We consider two prior distributions for \(\Delta\).
Weakly informative prior
This prior reflects little prior knowledge about the treatment effect: \[\Delta \sim N(0, 5^2)\]
It is centred at 0, so it does not assume benefit or harm in advance
Its 95% prior interval is approximately \((-9.8,\ 9.8)\), which is very wide relative to the MCID
In practice, this prior contributes very little information
Informative prior
This prior reflects earlier evidence, such as a pilot study or phase II trial, suggesting a modest positive effect: \[\Delta \sim N(0.5, 1^2)\]
It is centred at 0.5, suggesting a positive effect on average
Its 95% prior interval is approximately \((-1.5,\ 2.5)\), so it still allows no effect and harmful effects
Compared with the weak prior, it contributes more information and can reduce the amount of trial data needed to reach a conclusion
Figure 1: Prior distributions on Delta. The weakly informative prior expresses minimal prior knowledge. The informative prior reflects a pilot study suggesting modest benefit.
Bayesian Decision Rule
At the end of the trial, we compute the posterior probability that the treatment is better than control.
We declare the trial successful if
\[\Pr(\Delta > 0 \mid \text{data}) > 0.975.\]
In words, we require the posterior probability of benefit to exceed 97.5%.
This is a stringent superiority rule. In settings like this one, it is often viewed as broadly comparable to a conventional frequentist standard, although it is not identical to a two-sided \(p < 0.05\) test.
Power Condition
To determine the sample size, we ask the following question:
If the true treatment effect equals the MCID, how often will this Bayesian decision rule declare success?
So we look for the smallest \(n\) such that, when the true effect is \(\Delta = 1\), the probability of success is at least 0.80:
This plays the same role as power in a frequentist design: it tells us how likely the trial is to detect a clinically meaningful effect when that effect is truly present.
Normal-Normal Posterior
Because both the prior and the sampling model are normal, the posterior distribution is also normal.
Given the observed mean difference \(d = \bar{Y}_T - \bar{Y}_C\),
This formula shows that the posterior mean is a weighted average of:
the prior mean \(\mu_0\), and
the observed treatment effect \(d\)
As the sample size increases, the data become more precise and carry more weight in the posterior.
Code
# Parameterssigma <-2# SD per groupmcid <-1# MCIDgamma <-0.975# posterior probability thresholdn_sim <-10000set.seed(123)# Two priors to comparepriors <-list("N(0,5^2)"=c(mean =0, sd =5),"N(0.5,1^2)"=c(mean =0.5, sd =1))# Simulate one trial and return P(Delta > 0 | data)run_bayes_trial <-function(n, true_delta, sigma, prior_mean, prior_sd) { y_trt <-rnorm(n, mean = true_delta, sd = sigma) y_ctrl <-rnorm(n, mean =0, sd = sigma) d <-mean(y_trt) -mean(y_ctrl)# Normal-Normal posterior se2 <-2* sigma^2/ n prec_prior <-1/ prior_sd^2 prec_lik <-1/ se2 prec_post <- prec_prior + prec_lik mu_post <- (prec_prior * prior_mean + prec_lik * d) / prec_post sd_post <-sqrt(1/ prec_post)# P(Delta > 0 | data)1-pnorm(0, mean = mu_post, sd = sd_post)}
Operating Characteristics by Simulation
Even though the decision rule is Bayesian, we can still evaluate its performance using repeated simulation.
In particular, we examine:
False positive rate: how often the rule declares success when the true effect is \(\Delta = 0\)
Power: how often the rule declares success when the true effect is \(\Delta = 1\), the MCID
This is an important idea in Bayesian trial design:
we can use Bayesian inference for the final decision, while still checking frequentist-style operating characteristics such as false positive rate and power.
Minimum sample size meeting operating characteristic targets (false positive rate <= 5%, power >= 80%) by prior distribution.
Prior
n per arm
Total n
False Positive Rate
Power
N(0,5^2)
63
126
0.024
0.801
N(0.5,1^2)
61
122
0.028
0.804
Operating characteristics of the Bayesian design under two priors. The success rule is P(Delta > 0 | data) > 0.975, evaluated at Delta = 0 (false positive rate) and Delta = 1 (MCID, power). Dashed lines show the targets. Vertical dotted lines mark the minimum n for each prior.
How prior information changes the design
Table 1: Design comparison across frequentist and two Bayesian designs. All designs target 80% power at the MCID with false positive rate controlled at 5%.
Frequentist
Bayesian (Weak Prior)
Bayesian (Informative Prior)
Sample size (per arm)
63
63
61
Total sample size
126
126
122
Success rule
p < 0.05
P(Delta > 0 | data) > 0.975
P(Delta > 0 | data) > 0.975
Power condition
80% power at Delta = MCID
80% success at Delta = MCID
80% success at Delta = MCID
Prior belief
None
N(0, 25)
N(0.5, 1)
All three designs are being evaluated against the same practical standards:
they should have at least 80% power when the true effect equals the MCID, and
they should keep the false positive rate acceptably low
The main lessons are:
The weakly informative Bayesian design gives a sample size very similar to the frequentist design, because the prior adds little information
The informative Bayesian design can require fewer patients, because prior evidence contributes information
In both Bayesian designs, the final result is a posterior distribution for \(\Delta\), not just a binary reject/do not reject decision
Bayesian inference does not automatically solve statistical power problems. Its main advantages are:
i) the ability to incorporate prior information naturally, and
ii) the natural extension to adaptive monitoring and other flexible trial design features.
Connection to FDA 2026 Draft Guidance
The FDA draft guidance on Bayesian methods (January 2026) explicitly endorses exactly this approach: evaluating Bayesian designs via simulated operating characteristics to demonstrate that false positive rates and power meet regulatory expectations. This means Bayesian and frequentist designs can be held to the same accountability standard, while the Bayesian design offers richer inference.
References
Hernández, Glenn, Gustavo A Ospina-Tascón, Lucas Petri Damiani, Elisa Estenssoro, Arnaldo Dubin, Javier Hurtado, Gilberto Friedman, et al. 2019. “Effect of a Resuscitation Strategy Targeting Peripheral Perfusion Status Vs Serum Lactate Levels on 28-Day Mortality Among Patients with Septic Shock: The ANDROMEDA-SHOCK Randomized Clinical Trial.”Jama 321 (7): 654–64.
Zampieri, Fernando G, Lucas P Damiani, Jan Bakker, Gustavo A Ospina-Tascón, Ricardo Castro, Alexandre B Cavalcanti, and Glenn Hernandez. 2020. “Effects of a Resuscitation Strategy Targeting Peripheral Perfusion Status Versus Serum Lactate Levels Among Patients with Septic Shock. A Bayesian Reanalysis of the ANDROMEDA-SHOCK Trial.”American Journal of Respiratory and Critical Care Medicine 201 (4): 423–29.