Probability Rules
General Addition Rule: \(P(A\cup B)=P(A)+P(B)-P(A\cap B)\)
The reason behind this fact is that if there is if \(A\) and \(B\) are not disjoint, then some area is added twice when we calculate \(P\left(A\right)+P\left(B\right)\). To account for this, we simply subtract off the area that was double counted. If \(A\) and \(B\) are disjoint, \(P(A\cup B)=P(A)+P(B)\).
Complement Rule: \(P(A)+P(A^c)=1\)
This rule follows from the partitioning of the set of all events (\(S\)) into two disjoint sets, \(A\) and \(A^c\). We learned above that \(A \cup A^c = S\) and that \(P(S) = 1\). Combining those statements, we obtain the complement rule.
Completeness Rule: \(P(A)=P(A\cap B)+P(A\cap B^c)\)
This identity is just breaking the event \(A\) into two disjoint pieces.
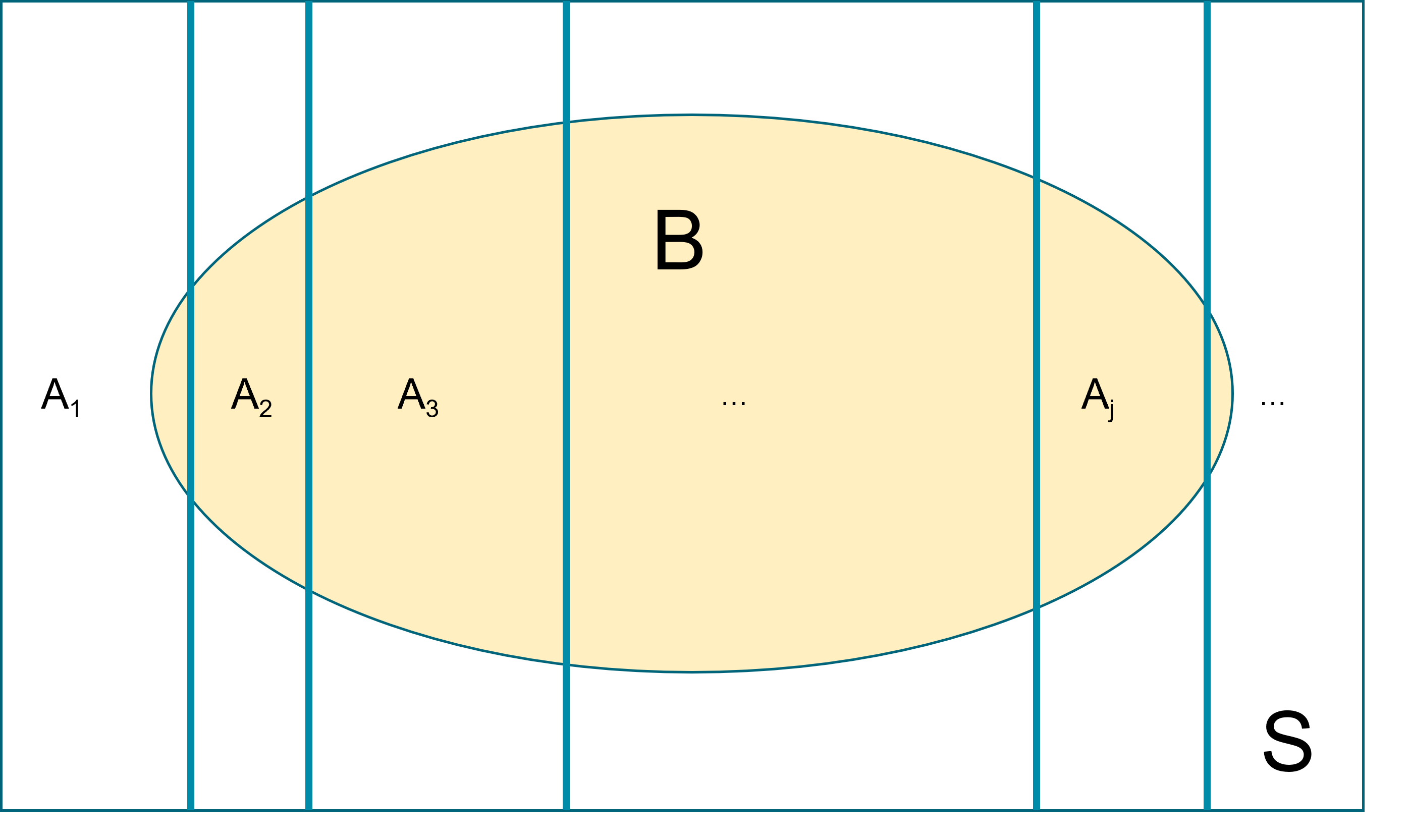
Law of total probability (unconditioned version): Let \(A_1, A_2, \ldots\) be events that form a partition of the sample space \(S\), Let \(B\) be any event. Then, \[P(B) = P(A_1 \cap B) + P(A_2 \cap B) + \ldots. \]
This law is key in deriving the marginal event probability in Bayes’ rule. Recall the HIV example from session 1, we have \(P(T^+) = P(T^+ \cap D^+)+P(T^+ \cap D^-)\).
Conditional Probability: The probability of even \(A\) occurring under the restriction that \(B\) is true is called the conditional probability of \(A\) given \(B\). Denoted as \(P(A|B)\).
In general we define conditional probability (assuming \(P(B) \ne 0\)) as \[P(A|B)=\frac{P(A\cap B)}{P(B)}\] which can also be rearranged to show \[\begin{aligned}
P(A\cap B) &= P(A\,|\,B)\,P(B) \\
&= P(B\,|\,A)\,P(A)
\end{aligned}\]
- Because the order doesn’t matter and \(P\left(A\cap B\right)=P\left(B\cap A\right)\).
- \(P(A|B) = 1\) means that the event \(B\) implies the event \(A\).
- \(P(A|B) = 0\) means that the event \(B\) excludes the possibility of event \(A\).
Suppose I know that whenever it rains there is 10% chance of being late at work, while the chance is only 1% if it does not rain. Suppose that there is 30% chance of raining tomorrow; what is the chance of being late at work?
Denote with event \(A\) as “I will be late to work tomorrow” and event \(B\) as “It is going to rain tomorrow”
\[\begin{aligned}
P(A) &= P(A\mid B)P(B) + P(A \mid B^c) P(B^c) \\
&= 0.1\times 0.3+0.01\times 0.7=0.037
\end{aligned}\]
Independent: Two events \(A\) and \(B\) are said to be independent if \(P(A\cap B)=P(A)P(B)\).
What independence is saying that knowing the outcome of event \(A\) doesn’t give you any information about the outcome of event \(B\). If \(A\) and \(B\) are independent events, then \(P(A|B) = P(A)\) and \(P(B|A) = P(B)\).
In simple random sampling, we assume that any two samples are independent. In cluster sampling, we assume that samples within a cluster are not independent, but clusters are independent of each other.
Assumptions of independence and non-independence in statistical modelling are important.
In linear regression, for example, correct standard error estimates rely on independence amongst observations.
In analysis of clustered data, non-independence means that standard regression techniques are problematic.
Bayes’ Rule: This arises naturally from the rule on conditional probability. Since the order does not matter in \(A \cap B\), we can rewrite the equation:
\[\begin{aligned}
P(A\mid B) &= \frac{P(A \cap B) }{P(B)}\\
&= \frac{P(B \cap A)}{P(B)}\\
&= \frac{P(B\mid A)P(A) }{P(B)}\\
&= \frac{P(B\mid A)P(A) }{P(B \cap A) + P(B \cap A^C)}\\
&= \frac{P(B\mid A)P(A) }{P(B\mid A)P(A) + P(B\mid A^C)P(A^C)}
\end{aligned}\]